12 Jul 2018
I Built a Go Plugin for Opensource Timeseries Database
Crosspost from Alpaca’s Medium Account.
Since this post, I’ve update the Crypto Go Plugin to handle more complexity and use cases. You can see the most recent version here.
A College Intern Builds a Go Plugin for Opensource Timeseries Database

Hey all! I’m Ethan and recently started working for
Alpaca as a Software Engineering Intern! For my first
task, I created a Go plugin for Alpaca’s open source timeseries database
MarketStore server that fetches and
writes Binance minute-level.
You might be wondering — What is MarketStore? MarketStore is a database server
written in Go that helps users handle large amounts of
financial data. Inside of MarketStore, there are Go plugins that allow users to
gather important financial and crypto data from third party sources.
For this blog post, I’ll be going over how I created the plugin from start to
finish in three sections: Installing MarketStore, understanding MarketStore’s
plugin structure, creating the Go plugin., and installing the Go plugin.
Experience Installing and Running MarketStore Locally
First, I set up MarketStore locally. I installed the latest version of Go and
started going through the installation process outlined in MarketStore’s README.
All the installation commands worked swimmingly, but when I tried to run
marketstore using
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ marketstore -config mkts.yml
I got this weird error:
/usr/local/go/src/fmt/print.go:597:CreateFile/go/src/github.com/alpacahq/marketstore/executor/wal.go:87open /project/data/mktsdb/WALFile.1529203211246361858.walfile: no such file or directory: Error Creating WAL File
I was super confused and couldn’t find any other examples of this error online.
After checking and changing permissions in the directory, I realized my
mkts.yml file configuration root_directory was incorrect. To resolve this, I
changed mkts.yml from
root_directory: /project/data/mktsdb
To
root_directory: /home/ethanc/go/bin/src/github.com/alpacahq/marketstore/project/data/mktsdb
and reran
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ marketstore -config mkts.yml
This time, everything worked fine and I got this output:
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ marketstore -config mkts.yml
…
I0621 11:37:52.067803 27660 log.go:14] Launching heartbeat service…
I0621 11:37:52.067856 27660 log.go:14] Enabling Query Access…
I0621 11:37:52.067936 27660 log.go:14] Launching tcp listener for all services
…
To enable the gdaxfeeder plugin which grabs data from a specified
cryptocurrency, I uncommented these lines in the mkts.yml file:
bgworkers:
- module: gdaxfeeder.so
name: GdaxFetcher
config:
query_start: "2017-09-01 00:00"
and reran
ethanc@ethanc-Inspiron-5559:~$ marketstore -config mkts.yml
which yielded:
…
I0621 11:44:27.248433 28089 log.go:14] Enabling Query Access…
I0621 11:44:27.248448 28089 log.go:14] Launching tcp listener for all services…
I0621 11:44:27.254118 28089 gdaxfeeder.go:123] lastTimestamp for BTC = 2017–09–01 04:59:00 +0000 UTC
I0621 11:44:27.254189 28089 gdaxfeeder.go:123] lastTimestamp for ETH = 0001–01–01 00:00:00 +0000 UTC
I0621 11:44:27.254242 28089 gdaxfeeder.go:123] lastTimestamp for LTC = 0001–01–01 00:00:00 +0000 UTC
I0621 11:44:27.254266 28089 gdaxfeeder.go:123] lastTimestamp for BCH = 0001–01–01 00:00:00 +0000 UTC
I0621 11:44:27.254283 28089 gdaxfeeder.go:144] Requesting BTC 2017–09–01 04:59:00 +0000 UTC — 2017–09–01 09:59:00 +0000 UTC
…
Now that I got MarketStore running, I used Jupyter notebooks and tested out the
commands listed in this Alpaca
tutorial
and got the same results. You can read more about how to run MarketStore in
MarketStore’s
README,
Alpaca’s
tutorial,
and this thread.
Understanding how MarketStore Plugins work
After installing, I wanted to understand how their
MarketStore repository works and how
their current Go plugins work. Before working in Alpaca, I didn’t have any
experience with the Go programming language. So, I completed the Go’s “A Tour
of Go” tutorial to get a general feel of the
language. Having some experience with C++ and Python, I saw a lot of
similarities and found that it wasn’t as difficult as I thought it would be.
Creating a MarketStore Plugin
To get started, I read the MarketStore Plugin
README.
To summarize at a very high level, there are two critical Go features which
power plugins: Triggers and BgWorkers. You use triggers when you want your
plugin to respond when certain types data are written to your MarketStore’s
database. You would use BgWorkers if you want your plugin to run in the
background.
I only needed to use the BgWorker feature because my plugin’s goal is to collect
data outlined by the user in the mkts.yml configuration file.
To get started, I read the code from the
gdaxfeeder
plugin which is quite similar to what I wanted to do except that I’m trying to
get and write data from the Binance exchange instead of the GDAX exchange.
I noticed that the gdaxfeeder used a GDAX Go
Wrapper, which got its historical
price data public endpoint. Luckily, I found a Go Wrapper for
Binance created by adshao that has the
endpoints which retrieves the current supported symbols as well as retrieves
Open, High, Low, Close, Volume data for any timespan, duration, or symbol(s) set
as the parameters.
To get started, I first created a folder called binancefeeder then created a
file called binancefeeder.go inside of that. I then first tested the Go
Wrapper for Binanceto see how to create a client and talk to the Binance API’s
Kline endpoint to get data:
I then ran this command in my root directory:
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ go run binancefeeder.go
and received the following response with Binance data:
&{1529553060000 6769.28000000 6773.91000000 6769.17000000 6771.34000000 32.95342700 1529553119999 223100.99470354 68 20.58056800 139345.00899491}
&{1529553120000 6771.33000000 6774.00000000 6769.66000000 6774.00000000 36.43794400 1529553179999 246732.39415947 93 20.42194600 138288.41850603}
…
So, it turns out that the Go Wrapper worked!
Next, I started brainstorming how I wanted to configure the Binance Go plugin. I
ultimately chose symbols, queryStart, queryEnd, and baseTimeframe as my
parameters since I wanted the user to query any specific symbol(s), start time,
end time, and timespan (ex: 1min). Then, right after my imports, I started
creating the necessary configurations and structure for BinanceFetcher for a
MarketStore plugin:
The FetcherConfig’s members are what types of settings the user can configure in
their configuration file (ex: mkts.yml) to start the plugin. The
BinanceFetcher’’s members are similar to the FetcherConfig with the addition of
the config member. This will be used in the Run function later.
After creating those structures, I started to write the background worker
function. To set it up, I created the necessary variables inside the
backgroundworker function
and
copied the recast function from the
gdaxfeeder.
The recast function uses Go’s Marshal function to encode the config JSON data
received, then sets a variable ret to an empty
interface called FetcherConfig. Then it
stores the parsed JSON config data in the ret variable and returns it:
Then inside the NewBgWorker function, I started to create a function to
determine and return the correct time format as well as set up the symbols, end
time, start time, and time duration. If there are no symbols set, by default,
the background worker retrieves all the valid cryptocurrencies and sets the
symbol member to all those currencies. It also checks the given times and
duration and sets them to defaults if empty. At the end, it returns the pointer
to BinanceFetcher as the bgworker.BgWorker:
Then, I started creating the Run function which is implemented by BgWorker
(see bgworker.go for more details). To get a better sense of how to handle
errors and write modular code in Go, I read the code for plugins
gdaxfeeder
and
polygon
plugins. The Run function receives the BinanceFetcher (which is dereferenced
since bgworker.BgWorker was the pointer to BinanceFetcher). Our goal for the
Run function is to call the Binance API’s endpoint with the given parameters for
OHLCV and retrieve the data and writes it to your MarketStore’s database.
I first created a new Binance client with no API key or secret since I’m using
their API’s public endpoints.
Then, to make sure that the BinanceFetcher doesn’t make any incorrectly
formatted API calls, I created a function to check the timestamp format using
regex and change it to the correct one. I had to convert the user’s given
timestamp to maintain consistency in the Alpaca’s utils.Timeframe which has a
lot of helpful functions but has different structure members than the one’s
Binance uses (ex: “1min” vs. “1m”). If the user uses an unrecognizable timestamp
format, it sets the baseTimeframe value to 1 minute:
The start and end time objects are already checked in the NewBgWorker function
and returns a null time.Time object if invalid. So, I only have to check if the
start time is empty and set it to the default string of the current Time. The
end time isn’t checked since it will be ignored if incorrect which will be
explained in the later section:
Now that the BinanceFetcher checks for the validity of its parameters and sets
it to defaults if its not valid, I moved onto programming a way to call the
Binance API.
To make sure we don’t overcall the Binance API and get IP banned, I used a for
loop to get the data in intervals. I created a timeStart variable which is
first set to the given time start and then created a timeEnd variable which is
300 times the duration plus the timeStart’s time. At the beginning of each
loop after the first one, the timeStart variable is set to timeEnd and the
timeEnd variable is set to 300 times the duration plus the timeStart’s time:
When it reaches the end time given by the user, it simply alerts the user
through glog and continues onward. Since this is a background worker, it needs
to continue to work in the background. Then it writes the data retrieved to the
MarketStore database. If invalid, the plugin will stop because I don’t want to
write garbage values to the database:
Installing Go Plugin
To install, I simply changed back to the root directory and ran:
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ make plugins
Then, to configure MarketStore to use my file, I changed my config file,
mkts.yml, to the following:
Then, I ran MarketStore:
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ marketstore -config mkts.yml
And got the following:
…
I0621 14:48:46.944709 6391 plugins.go:42] InitializeBgWorkers
I0621 14:48:46.944801 6391 plugins.go:45] bgWorkerSetting = &{binancefeeder.so BinanceFetcher map[base_timeframe:1Min query_start:2018–01–01 00:00 query_end:2018–01–02 00:00 symbols:[ETH]]}
I0621 14:48:46.952424 6391 log.go:14] Trying to load module from path: /home/ethanc/go/bin/bin/binancefeeder.so…
I0621 14:48:47.650619 6391 log.go:14] Success loading module /home/ethanc/go/bin/bin/binancefeeder.so.
I0621 14:48:47.651571 6391 plugins.go:51] Start running BgWorker BinanceFetcher…
I0621 14:48:47.651633 6391 log.go:14] Launching heartbeat service…
I0621 14:48:47.651679 6391 log.go:14] Enabling Query Access…
I0621 14:48:47.651749 6391 log.go:14] Launching tcp listener for all services…
I0621 14:48:47.654961 6391 binancefeeder.go:198] Requesting ETH 2018–01–01 00:00:00 +0000 UTC — 2018–01–01 05:00:00 +0000 UTC
…
Testing:
When I was editing my plugin and debugging, I often ran the binancefeeder.go
file:
ethanc@ethanc-Inspiron-5559:~/go/bin/src/github.com/alpacahq/marketstore$ go run binancefeeder.go
If I ran into an issue I couldn’t resolve, I used the equivalent print function
for Go (fmt). If there is an issue while running the plugin as part of
MarketStore via the marketstore -config mkts.yml command, I used the
glog.Infof() or glog.Errorf() function to output the corresponding error or
incorrect data value.
Lastly, I copied the gdaxfeeder test go
program
and simply modified it for my binancefeeder test go
program.
You’ve made it to the end of the blog post! Here’s the
link
to the Binance plugin if you want to see the complete code. If you want to see
all of MarketStore’s plugins, check out this
folder.
To summarize, if you want to create a Go extension for any open source
repository, I would first read the existing documentation whether it is a
README.md or a dedicated documentation website. Then, I would experiment
around the repositories code by changing certain parts of the code and see which
functions correspond with what action. Lastly, I would look over previous
extensions and refactor an existing one that seems close to your plugin idea.
Thanks for reading! I hope you take a look at the MarketStore repository and
test it out. If you have any questions, few free to comment below and I’ll try
to answer!
Special thanks to Hitoshi, Sho, Chris, and the rest of the Alpaca’s
Engineering team for their code reviews and help as well as Yoshi and Rao for
providing feedback for this post.
By: Ethan Chiu
Brokerage services are provided by Alpaca Securities LLC
(alpaca.markets), member FINRA/SIPC. Alpaca Securities
LLC is a wholly-owned subsidiary of AlpacaDB, Inc.
Follow **Alpaca on Medium, and
@AlpacaHQ on twitter.**
Commission Free Stock Trading API
http://alpaca.markets (Securities are offered through
Alpaca Securities LLC)
[Automation
Generation](https://medium.com/automation-generation?source=footer_card)
News and thought leadership on the changing landscape of automated investing.
Changing the market one algorithm at a time.
28 Feb 2018
I recently started working on a project that shows and analyzes real-time Conservative, Moderate, and Liberal viewpoints across social media called the United Timeline.
Here’s the mission statement:
“The media constantly bombards us with polarizing rhetoric that support our own viewpoints. Without viewing other perspectives, we create an echo chamber that limits the extent to which we can have an open dialogue that critically engages with important topics and situations. Ignoring arguments from the other political side creates divisiveness, furthering the divide between Americans and bringing no real progress when it comes to reforms and policies in Congress and elsewhere.
The United Timeline provides real-time social media posts and analysis of liberal, moderate, and conservative viewpoints. Our goal is to bridge the divide between liberals, conservatives, and moderates by sharing the current conversation from each side on social media.”
Currently, we show what Twitter news feeds would look like from those different viewpoints.To achieve this, I started out creating the Twitter timelines for Conservative, Moderate, and Liberal viewpoints. This was pretty straightforward. I created a Twitter account and created three different lists containing the most prominent and intelligent pundits from each side. Then, I simply embedded them side by side.
After that, I wanted to generate word clouds of the most recent Tweets. One way that instantly popped up in my mind was to simply use Twitter’s API. Unfortunately, the API has limits that would easily be passed for real-time analysis. Another method was using Selenium to constantly scrape the most recent Tweets. This would require me to create a server with a backend and also might not work since Twitter blocks scraping after a certain limit.
So, I created a way to analyze the 20 most recent Tweets from each list all in the client-side (no backend). As a result, I don’t have to rely on backend processing or worry about server costs. To analyze these Tweets in real time, I first analyzed how Twitter’s embedded lists load onto a site. I saw that the embedded link transformed into a asynchronous script, meaning it loads in the background of the website as the user interacts with the list. As a result, I programmed a script which checks when the async Twitter script is loaded for each list. Afterwards, it grabs the top 20 Tweets’ text content using jQuery to identify the class names. Then, I use regex to eliminate any urls, @ tags, or punctuation so that only words are generated in the word clouds. After that, I calculate the word frequency and format that into a list that the wordcloud2 Javascript library can understand.
So, my script allows the user to see realtime graphs of the 20 most recent Tweets from each list every time he or she refreshes the page!
Here’s the code:
$( document ).ready(function() {
var $canvas = $('#word_cloud');
//Temp solution since Twitter uses async for embeded links.
generateWordCloud();
});
//Edited https://stackoverflow.com/questions/30906807/word-frequency-in-javascript
function wordFreq(string) {
// get rid of urls, @ mentions, punctionation + spaces
var no_url = string.replace(/(?:https?|ftp):\/\/[\n\S]+/g, '').replace(/\S*@\S*\s?/g, "").replace(/(?:(the|a|an|and|of|what|to|for|about) +)/g, "").replace(/[.,\/#!$%\^&\*;:{}=\-_`~()]/g,"");
var words = no_url.replace(/[.]/g, '').split(/\s/);
var freqMap = {};
words.forEach(function(w) {
if (!freqMap[w]) {
freqMap[w] = 0;
}
freqMap[w] += 1;
});
return freqMap;
}
function generateWordFreqs(raw_data, name) {
var tweets = [];
for(var i = 0; i<raw_data.length; i++){
tweets.push(raw_data[i].innerText);
}
//Regex to elimate tags, etc. + join words into one coherent group
tweets = tweets.join(' ');
listA = wordFreq(tweets);
var list = [];
for (var key in listA)
{
list.push([key, listA[key]*5]);
}
WordCloud.minFontSize = "15px";
WordCloud($('#' + name + '_word_cloud')[0], { list: list });
}
function generateWordCloud(){
setTimeout(
function() {
//Set up variables, get document values from iframes loaded asyncronously
//Work around for not being able to explicitly call $("#twitter-widget-.....")
var liberal = $(document.getElementById('twitter-widget-0').contentWindow.document).find(".timeline-Tweet-text");
var moderate = $(document.getElementById('twitter-widget-1').contentWindow.document).find(".timeline-Tweet-text");
var conservative = $(document.getElementById('twitter-widget-2').contentWindow.document).find(".timeline-Tweet-text");
//Generate Word Clouds
generateWordFreqs(liberal, "liberal");
generateWordFreqs(moderate, "moderate");
generateWordFreqs(conservative, "conservative");
}, 250);
}
Here’s the link where you can see this all in action.

Obviously, this isn’t the prettiest solution out there. I could of used recursion and for loops to eliminate some repetition, but I feel like this is the clearest explanation. For a full list of my other attempts for analyzing the Tweets in realtime completely client-side, please check out the Javascript file on Github.
Since this script only works for 20 of the most recent Tweets, I’m most likely going to create a Python backend to process more Tweets (like every Tweet in a day) and present different word clouds daily. This would also allow me to use libraries such as NTLK to filter out connecting words.
We are currently working on adding more analytic tools and integrations. This website is completely open source and open to contributions. We are currently working on adding more analytic tools and integrations. If you have any suggestions/concerns, feel free to open up an issue over here.
03 Feb 2018
Recently, for our research project, we worked on identifying hate on anonymous platforms.
Here’s an example of a graph of the percentage of the top 15 hate words with dummy data in a random server:
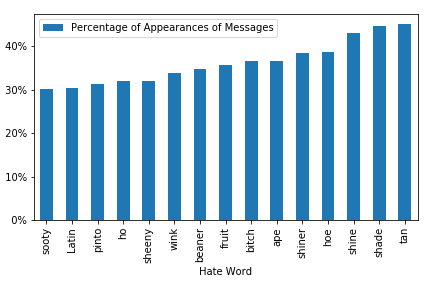
We were inspired by the method of identifying hate outlined in the paper “Kek, Cucks, and God Emperor Trump: A Measurement Study of 4chan’s Politically Incorrect Forum and Its Effects on the Web”.
To code this up, I first had to import a list of hate words. I used the library that the aforementioned paper used: Hatebase. I used a python wrapper to get the top 1000 US hate words:
key = "ENTER_YOU_KEY_HERE"
from json import loads
from hatebase import HatebaseAPI
hatebase = HatebaseAPI({"key": key})
#"language": "eng"
pagenumber = 1
responses = []
#Loads top 1000 results
while pagenumber <= 11:
filters = {"country":"US", "page": str(pagenumber)}
output = "json"
query_type = "vocabulary"
response = hatebase.performRequest(filters, output, query_type)
# convert to Python object
responses.append(loads(response))
pagenumber += 1
print "Done getting API results"
Then, I processed the JSON data received from the API by using Python’s convenient iteritems() function for dictionaries:
#Process Hate Words
data = []
for r in responses:
data.append(r["data"])
#print len(data)
listofHatewords = []
#print len(data)
for z in data:
for a, v in z.iteritems():
for b in v:
listofHatewords.append(b["vocabulary"])
print listofHatewords
listofHatewords = list(OrderedDict.fromkeys(listofHatewords))
print len(listofHatewords)
Then, I used this code from StackOverflow to find different forms of the hate words:
#NTLK
#FROM: https://stackoverflow.com/a/45158719/4698963
from nltk.corpus import wordnet as wn
#We'll store the derivational forms in a set to eliminate duplicates
index2 = 0
for word in listofHatewords:
forms = set()
for happy_lemma in wn.lemmas(word): #for each "happy" lemma in WordNet
forms.add(happy_lemma.name()) #add the lemma itself
for related_lemma in happy_lemma.derivationally_related_forms(): #for each related lemma
forms.add(related_lemma.name()) #add the related lemma
versionsOfWord[index2] = forms
index2 += 1
print len(versionsOfWord)
Then, I initialize 4 lists, size 1000, to gather as much info as possible about hate words and its occurrences in messages such as ID of the message and message content associated with the hate word:
frequency = []
versionsOfWord = []
#frequencyID = []
frequencyTime = []
listmessageID = []
listauthors = []
frequencyIndex = []
for x in range(0, 1000):
frequency.append(0)
"""
for x in range(0, 1000):
frequencyID.append([])
"""
for x in range(0, 1000):
listmessageID.append([])
for x in range(0, 1000):
listauthors.append([])
for x in range(0, 1000):
frequencyTime.append([])
for x in range(0, 1000):
frequencyIndex.append([])
for x in range(0, 1000):
versionsOfWord.append([])
For the main loop, I first search through each message in the messages list (which was imported from prior data). I then make that message lowercase. After, I split it into a words and see if hate words or its forms are in the messages. I also check for censored words (ex: “nger”) via difflib library:
totalNumberofWords = 0
counter = 0
print len(message)
print len(messageID)
print len(timestamps)
for m, m_id, date, a_id in zip(message, messageID, timestamps, authorID):
#print m
totalNumberofWords += len(m)
lower = m.lower()
index = 0
if counter%100000==0:
print counter
#print counter
#Need to tokenize to get all frequencies
for word in listofHatewords:
wordLowered = word.lower()
listof_lower = lower.split(" ")
similarWords = versionsOfWord[index]
#matchesHate = difflib.get_close_matches(word, listof_lower, 1, .5)
#https://docs.python.org/2/library/difflib.html
#Else if check the NTLK forms of words
#Check if there are versions of the word first though
#TOOK out "word in lower" since it was inaccurate
if wordLowered in listof_lower or len(difflib.get_close_matches(wordLowered, listof_lower, 1, .75)) >= 1:
frequency[index]+=1
frequencyIndex[index].append(counter)
#frequencyID[index].append(str(m_id) + " " + m)
frequencyTime[index].append(date)
listmessageID[index].append(m_id)
listauthors[index].append(a_id)
elif len(similarWords) > 0:
#found = False
for a in similarWords:
aLowered = a.lower()
if aLowered in listof_lower or len(difflib.get_close_matches(aLowered, listof_lower, 1, .75)) >= 1:
#found = True
frequency[index]+=1
frequencyIndex[index].append(counter)
#frequencyID[index].append(str(m_id) + " " + m)
frequencyTime[index].append(date)
listmessageID[index].append(m_id)
listauthors[index].append(a_id)
#print "test" + str(counter)
break
#Increase index to make sense
if index >= len(listofHatewords):
print "Length error"
index+=1
counter += 1
Here is how I saved it in a JSON file:
#Process data
jsonList = []
for i in range(0,1000):
jsonList.append({'hateword': listofHatewords[i], 'messageID': listmessageID[i], 'authorID':listauthors[i], 'frequency': frequency[i], 'frequencyIndex':frequencyIndex[i], 'frequencyTime':frequencyTime[i]})
#print(json.dumps(jsonList, indent = 1))
#Put to file
import simplejson
import time
timestr = time.strftime("%Y%m%d-%H%M%S")
try:
f = open(ChannelName + 'Allfrequencies' + str(timestr) +'.json', 'w')
simplejson.dump(jsonList, f)
f.close()
except NameError:
print "Almost erased" + ChannelName + "Allfrequencies.json! Be careful!!!"
Here is how I graphed it in Pandas:
'''
Graphs percentage of mentions of ____ hate word in posts
'''
#print totalNumberofWords
#print frequency
#TODO percentages + save list of hate words into file for further analysis
#Test for every word
#Create matrix where this is the message ||
#parse vector => how many words is mentioned
#counter vectorizer => ski kit learn. vocabulary is list of 1000 words
#^count how many times a word occurs
#Sum of rows
#Find which of the words occur the most
#Use pandas
df = pd.DataFrame({'words':listofHatewords, 'frequency':frequency})
#Sort
df = df.sort_values('frequency')
#print df
#Cut to top ten most popular posts
gb = df.tail(15)
#total number of words
lengthOfMessages = len(message)
#print gb
#Calculate percentage
gb["percentage"] = gb["frequency"]/lengthOfMessages
#print df
del gb["frequency"]
#Rename Columns
gb.columns = ["Hate Word", "Percentage of Appearances of Messages"]
print gb
#Graph percentages
ax = gb.set_index('Hate Word').plot(kind='bar')
plt.tight_layout()
vals = ax.get_yticks()
ax.set_yticklabels(['{:3.0f}%'.format(x*100) for x in vals])
im = ax
image = im.get_figure()
image.savefig(ChannelName + 'HateSpeechBar.png')
And that’s it! This code does not detect the context of conversation such as sarcasm and solely tests for existence of words in messages.
14 Jan 2018
I think it’s important to study humanities because many programmers don’t understand the ramifications of the technology they create.
For example, Facebook and other social media platforms have such strong algorithms and information tools that basically grant any advertiser to target any demographic they want by gender, age, etc. So, with enough money, any entity can target a certain group of people and change their opinion pretty easily. Thus, platforms like Facebook allow entities to manufacture consent on any group of people if they have enough money.
When I first started learning about computer science, I dreamed about working for the top tech companies because of how cool it was. I just wanted to create the coolest and most advanced technology out there. Little did I understand the great harm some technology like Facebook does to people.
For example, Facebook utilizes machine learning and other optimization tools to basically create an instant gratification cycle which keeps users hooked onto the site as long as possible. As a result, people see content that Facebook’s algorithms deem they will like which sometimes includes misinformation and creates echo chambers. For example, if a user was a troll and loved Donald Trump, he or she might have been shown misinformation like Pizzagate. That person might become so convinced that that information is true that he or she might bring a gun to that pizza place.
Personally speaking, studying courses in the humanities at my community college such as Economics and English classes and doing interdisciplinary research have really changed my mindset as a person and programmer. For example, in my latest English classes, we read literature such as Noam Chomsky’s Media Control and articles like “Teen Depression and Anxiety: Why the Kids Are Not Alright”. Those types of literature woke me up in a sense. Before then, I had attended a lot of hackathons creating a vast array of cool technology with other programmers. What I dreamed of was becoming a software programmer at a big tech company like Facebook. I never thought about the negative effects of those types of technology. All I saw when I dreamed about working for these companies was creating impactful technology that make our world more connective. After reading writings like the ones mentioned above in the past semesters, I’ve realized the importance of truly understanding the consequences and the multifaceted nature of creating novel technologies.
Moreover, studying these types of courses in humanities motivated me to do my own investigation and research. I talked to my cousin who is only 6. Guess what? He plays Minecraft and voice chats with random people daily!!! To me, that’s frightening. While technology like this VoIP seem cool due to its low barrier of entry, accessibility, and freedom from consequences, it also paves an easy way for trolls to bully others like young kids with no consequences. I also talked to a friend who I gamed with and was shock to have heard that he attempted suicide a few years ago at the age of 12. Based on my conversations, it was clear it stemmed from the messages he got on social platforms and the sense of needing to fit in based on the image that social media paints.
Nevertheless, I think platforms like Facebook are realizing the harm they are creating after seeing former executives speak out like Chamath Palihapitiya. Facebook recently announced they are changing the newsfeed to show more friends and family posts, thus creating more meaningful conversations. I’m also happy to see powerful and influential tech moguls such as Elon Musk create initiatives like OpenAI which focus on creating a safe pathway to artificial intelligence. Hopefully, other powerful tech executives follow suit before technology create long term damage.
Thus, I think it’s important that programmers study subjects in the humanities such as psychology, history, and ethics so that they have a strong understanding of what they are creating.
29 Dec 2017
For my research project, I wanted to get a better sense of how many Discord servers exist, considering there was no official number out there.
So, I searched on Google for a list of Discord servers and found a few websites.
I started out with finding a way to scrape the first website that was listed when I searched for Discord servers’ list: https://discord.me/servers/1
There wasn’t an official number of Discord servers listed so I investigated how the website looked like. It was fairly simple with buttons “Next” and “Previous” that helped navigate between different pages of Discord servers.
Using Inspect Element, I identified the element associated with the titles of the channels as well as identified the element associated with the “next” button. Then, using Selenium, I constructed a loop which clicked on the next button, waited for 3 seconds, and added all the servers to the list:
# The path works because I have moved the "chromedriver" file in /usr/local/bin
browser = webdriver.Chrome(executable_path='/usr/bin/chromedriver')
listofChannels=[]
#https://discord.me/servers/1
browser.get('https://discord.me/servers/1')
a = 0
#Use infinite loop since the total number of pages is unknown.
#At least in jupyter notebooks, it'll stop when it can't find the "Next" button on the last page)
while True:
names = browser.find_elements_by_class_name("server-name")
for name in names:
listofChannels.append(name.text)
moveforward = browser.find_elements_by_xpath("//*[contains(text(), 'Next')]")[0]
moveforward.click()
print a
a+=1
time.sleep(3)
Then, I used the Pandas library to make sure there were no duplicate servers:
#Find Duplicates using Pandas library
cleanList = pd.unique(listofChannels).tolist()
Finally, to tally up all of the servers, I just used Python’s len() function:
count = len(cleanList)
print count
In the end, I counted 13,040 servers listed on the discord.me site.