03 Feb 2018
Recently, for our research project, we worked on identifying hate on anonymous platforms.
Here’s an example of a graph of the percentage of the top 15 hate words with dummy data in a random server:
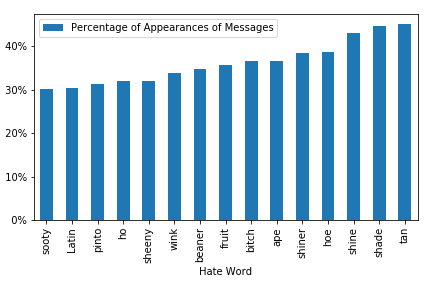
We were inspired by the method of identifying hate outlined in the paper “Kek, Cucks, and God Emperor Trump: A Measurement Study of 4chan’s Politically Incorrect Forum and Its Effects on the Web”.
To code this up, I first had to import a list of hate words. I used the library that the aforementioned paper used: Hatebase. I used a python wrapper to get the top 1000 US hate words:
key = "ENTER_YOU_KEY_HERE"
from json import loads
from hatebase import HatebaseAPI
hatebase = HatebaseAPI({"key": key})
#"language": "eng"
pagenumber = 1
responses = []
#Loads top 1000 results
while pagenumber <= 11:
filters = {"country":"US", "page": str(pagenumber)}
output = "json"
query_type = "vocabulary"
response = hatebase.performRequest(filters, output, query_type)
# convert to Python object
responses.append(loads(response))
pagenumber += 1
print "Done getting API results"
Then, I processed the JSON data received from the API by using Python’s convenient iteritems() function for dictionaries:
#Process Hate Words
data = []
for r in responses:
data.append(r["data"])
#print len(data)
listofHatewords = []
#print len(data)
for z in data:
for a, v in z.iteritems():
for b in v:
listofHatewords.append(b["vocabulary"])
print listofHatewords
listofHatewords = list(OrderedDict.fromkeys(listofHatewords))
print len(listofHatewords)
Then, I used this code from StackOverflow to find different forms of the hate words:
#NTLK
#FROM: https://stackoverflow.com/a/45158719/4698963
from nltk.corpus import wordnet as wn
#We'll store the derivational forms in a set to eliminate duplicates
index2 = 0
for word in listofHatewords:
forms = set()
for happy_lemma in wn.lemmas(word): #for each "happy" lemma in WordNet
forms.add(happy_lemma.name()) #add the lemma itself
for related_lemma in happy_lemma.derivationally_related_forms(): #for each related lemma
forms.add(related_lemma.name()) #add the related lemma
versionsOfWord[index2] = forms
index2 += 1
print len(versionsOfWord)
Then, I initialize 4 lists, size 1000, to gather as much info as possible about hate words and its occurrences in messages such as ID of the message and message content associated with the hate word:
frequency = []
versionsOfWord = []
#frequencyID = []
frequencyTime = []
listmessageID = []
listauthors = []
frequencyIndex = []
for x in range(0, 1000):
frequency.append(0)
"""
for x in range(0, 1000):
frequencyID.append([])
"""
for x in range(0, 1000):
listmessageID.append([])
for x in range(0, 1000):
listauthors.append([])
for x in range(0, 1000):
frequencyTime.append([])
for x in range(0, 1000):
frequencyIndex.append([])
for x in range(0, 1000):
versionsOfWord.append([])
For the main loop, I first search through each message in the messages list (which was imported from prior data). I then make that message lowercase. After, I split it into a words and see if hate words or its forms are in the messages. I also check for censored words (ex: “nger”) via difflib library:
totalNumberofWords = 0
counter = 0
print len(message)
print len(messageID)
print len(timestamps)
for m, m_id, date, a_id in zip(message, messageID, timestamps, authorID):
#print m
totalNumberofWords += len(m)
lower = m.lower()
index = 0
if counter%100000==0:
print counter
#print counter
#Need to tokenize to get all frequencies
for word in listofHatewords:
wordLowered = word.lower()
listof_lower = lower.split(" ")
similarWords = versionsOfWord[index]
#matchesHate = difflib.get_close_matches(word, listof_lower, 1, .5)
#https://docs.python.org/2/library/difflib.html
#Else if check the NTLK forms of words
#Check if there are versions of the word first though
#TOOK out "word in lower" since it was inaccurate
if wordLowered in listof_lower or len(difflib.get_close_matches(wordLowered, listof_lower, 1, .75)) >= 1:
frequency[index]+=1
frequencyIndex[index].append(counter)
#frequencyID[index].append(str(m_id) + " " + m)
frequencyTime[index].append(date)
listmessageID[index].append(m_id)
listauthors[index].append(a_id)
elif len(similarWords) > 0:
#found = False
for a in similarWords:
aLowered = a.lower()
if aLowered in listof_lower or len(difflib.get_close_matches(aLowered, listof_lower, 1, .75)) >= 1:
#found = True
frequency[index]+=1
frequencyIndex[index].append(counter)
#frequencyID[index].append(str(m_id) + " " + m)
frequencyTime[index].append(date)
listmessageID[index].append(m_id)
listauthors[index].append(a_id)
#print "test" + str(counter)
break
#Increase index to make sense
if index >= len(listofHatewords):
print "Length error"
index+=1
counter += 1
Here is how I saved it in a JSON file:
#Process data
jsonList = []
for i in range(0,1000):
jsonList.append({'hateword': listofHatewords[i], 'messageID': listmessageID[i], 'authorID':listauthors[i], 'frequency': frequency[i], 'frequencyIndex':frequencyIndex[i], 'frequencyTime':frequencyTime[i]})
#print(json.dumps(jsonList, indent = 1))
#Put to file
import simplejson
import time
timestr = time.strftime("%Y%m%d-%H%M%S")
try:
f = open(ChannelName + 'Allfrequencies' + str(timestr) +'.json', 'w')
simplejson.dump(jsonList, f)
f.close()
except NameError:
print "Almost erased" + ChannelName + "Allfrequencies.json! Be careful!!!"
Here is how I graphed it in Pandas:
'''
Graphs percentage of mentions of ____ hate word in posts
'''
#print totalNumberofWords
#print frequency
#TODO percentages + save list of hate words into file for further analysis
#Test for every word
#Create matrix where this is the message ||
#parse vector => how many words is mentioned
#counter vectorizer => ski kit learn. vocabulary is list of 1000 words
#^count how many times a word occurs
#Sum of rows
#Find which of the words occur the most
#Use pandas
df = pd.DataFrame({'words':listofHatewords, 'frequency':frequency})
#Sort
df = df.sort_values('frequency')
#print df
#Cut to top ten most popular posts
gb = df.tail(15)
#total number of words
lengthOfMessages = len(message)
#print gb
#Calculate percentage
gb["percentage"] = gb["frequency"]/lengthOfMessages
#print df
del gb["frequency"]
#Rename Columns
gb.columns = ["Hate Word", "Percentage of Appearances of Messages"]
print gb
#Graph percentages
ax = gb.set_index('Hate Word').plot(kind='bar')
plt.tight_layout()
vals = ax.get_yticks()
ax.set_yticklabels(['{:3.0f}%'.format(x*100) for x in vals])
im = ax
image = im.get_figure()
image.savefig(ChannelName + 'HateSpeechBar.png')
And that’s it! This code does not detect the context of conversation such as sarcasm and solely tests for existence of words in messages.
14 Jan 2018
I think it’s important to study humanities because many programmers don’t understand the ramifications of the technology they create.
For example, Facebook and other social media platforms have such strong algorithms and information tools that basically grant any advertiser to target any demographic they want by gender, age, etc. So, with enough money, any entity can target a certain group of people and change their opinion pretty easily. Thus, platforms like Facebook allow entities to manufacture consent on any group of people if they have enough money.
When I first started learning about computer science, I dreamed about working for the top tech companies because of how cool it was. I just wanted to create the coolest and most advanced technology out there. Little did I understand the great harm some technology like Facebook does to people.
For example, Facebook utilizes machine learning and other optimization tools to basically create an instant gratification cycle which keeps users hooked onto the site as long as possible. As a result, people see content that Facebook’s algorithms deem they will like which sometimes includes misinformation and creates echo chambers. For example, if a user was a troll and loved Donald Trump, he or she might have been shown misinformation like Pizzagate. That person might become so convinced that that information is true that he or she might bring a gun to that pizza place.
Personally speaking, studying courses in the humanities at my community college such as Economics and English classes and doing interdisciplinary research have really changed my mindset as a person and programmer. For example, in my latest English classes, we read literature such as Noam Chomsky’s Media Control and articles like “Teen Depression and Anxiety: Why the Kids Are Not Alright”. Those types of literature woke me up in a sense. Before then, I had attended a lot of hackathons creating a vast array of cool technology with other programmers. What I dreamed of was becoming a software programmer at a big tech company like Facebook. I never thought about the negative effects of those types of technology. All I saw when I dreamed about working for these companies was creating impactful technology that make our world more connective. After reading writings like the ones mentioned above in the past semesters, I’ve realized the importance of truly understanding the consequences and the multifaceted nature of creating novel technologies.
Moreover, studying these types of courses in humanities motivated me to do my own investigation and research. I talked to my cousin who is only 6. Guess what? He plays Minecraft and voice chats with random people daily!!! To me, that’s frightening. While technology like this VoIP seem cool due to its low barrier of entry, accessibility, and freedom from consequences, it also paves an easy way for trolls to bully others like young kids with no consequences. I also talked to a friend who I gamed with and was shock to have heard that he attempted suicide a few years ago at the age of 12. Based on my conversations, it was clear it stemmed from the messages he got on social platforms and the sense of needing to fit in based on the image that social media paints.
Nevertheless, I think platforms like Facebook are realizing the harm they are creating after seeing former executives speak out like Chamath Palihapitiya. Facebook recently announced they are changing the newsfeed to show more friends and family posts, thus creating more meaningful conversations. I’m also happy to see powerful and influential tech moguls such as Elon Musk create initiatives like OpenAI which focus on creating a safe pathway to artificial intelligence. Hopefully, other powerful tech executives follow suit before technology create long term damage.
Thus, I think it’s important that programmers study subjects in the humanities such as psychology, history, and ethics so that they have a strong understanding of what they are creating.
29 Dec 2017
For my research project, I wanted to get a better sense of how many Discord servers exist, considering there was no official number out there.
So, I searched on Google for a list of Discord servers and found a few websites.
I started out with finding a way to scrape the first website that was listed when I searched for Discord servers’ list: https://discord.me/servers/1
There wasn’t an official number of Discord servers listed so I investigated how the website looked like. It was fairly simple with buttons “Next” and “Previous” that helped navigate between different pages of Discord servers.
Using Inspect Element, I identified the element associated with the titles of the channels as well as identified the element associated with the “next” button. Then, using Selenium, I constructed a loop which clicked on the next button, waited for 3 seconds, and added all the servers to the list:
# The path works because I have moved the "chromedriver" file in /usr/local/bin
browser = webdriver.Chrome(executable_path='/usr/bin/chromedriver')
listofChannels=[]
#https://discord.me/servers/1
browser.get('https://discord.me/servers/1')
a = 0
#Use infinite loop since the total number of pages is unknown.
#At least in jupyter notebooks, it'll stop when it can't find the "Next" button on the last page)
while True:
names = browser.find_elements_by_class_name("server-name")
for name in names:
listofChannels.append(name.text)
moveforward = browser.find_elements_by_xpath("//*[contains(text(), 'Next')]")[0]
moveforward.click()
print a
a+=1
time.sleep(3)
Then, I used the Pandas library to make sure there were no duplicate servers:
#Find Duplicates using Pandas library
cleanList = pd.unique(listofChannels).tolist()
Finally, to tally up all of the servers, I just used Python’s len() function:
count = len(cleanList)
print count
In the end, I counted 13,040 servers listed on the discord.me site.
19 Dec 2017
Recently, I wrote about a script I wrote for extracting subreddit names from URLs.
From there, I programmed a way to extract the time from the JSON data so that I could eventually construct a time series using the Pandas library. Note that I had to take a substring of the result due to some bugs in the GoogleScraper:
#Process time stamps correctly for data.
#Note that some are in the general data instead of the correct time slot
timestamp=[]
for a in data:
for b in a['results']:
#Fix why none is not working
#workaround with length of 4?
if 'None' in b['time_stamp']:
timestamp.append(b['snippet'][0:12])
else:
timestamp.append(b['time_stamp'][0:12])
Next, I worked on programming a way to find more info about the subreddit and associated to said link. I originally tried to find a JSON dataset with information already or a list of subreddits with descriptions. Unfortunately, I couldn’t find any list that had ALL subreddits. So, I used the official reddit website to get the description utilizing their https://www.reddit.com/redditshttps://www.reddit.com/reddits website.
First, I had to setup Selenium. I had to install Selenium and Jupyter notebooks. It was pretty simple. Just had to install the package via terminal with apt-get and download the Chrome web driver from Google and move it to /usr/bin. I added the following libraries to the top of my code:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
After testing the Jupyter notebook to make sure that their libraries were running expectantly, I went back to the https://www.reddit.com/reddits website to identify patterns within classes and structure to extract descriptions. From there, I simply ran a for loop for the subreddit list which searched each of the subreddit names and then extracted the description of the first result (since those names in the list are 100% accurate). I also included a try and except loop to prevent a out of index error because if the surbeddit doesn’t have a description, the HTML element “md” is not created and thus would create an error that stops the whole script:
# Path = where the "chromedriver" file is
browser = webdriver.Chrome(executable_path='/usr/bin/chromedriver')
browser.get('https://www.reddit.com/reddits')
#Get info on each search term
inputBox = browser.find_element_by_name("q")
info = []
for channel in subReddits:
inputBox.clear()
inputBox.send_keys(channel)
inputBox.send_keys(Keys.ENTER)
time.sleep(3)
#find element
try:
elem = browser.find_elements_by_class_name("md")[1]
info.append(elem)
except IndexError:
info.append("")
#Solution to stale element issue since element changes from the original q element
inputBox = browser.find_element_by_name("q")
And finally, creating a table for readability:
#Combine Data for data processing
arrays = zip(links, subReddits, timestamp, info)
df = pd.DataFrame(data=arrays)
df
Full code:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import urllib, json
from pprint import pprint
import time
#Load Json
data = json.load(open('discordgg/December2016November2017.json'))
#Get Only Links from JSON
links=[]
for a in data:
for b in a['results']:
links.append(b['link'])
#pprint(b['link'])
#Process time stamps correctly for data.
#Note that some are in the general data instead of the correct time slot
timestamp=[]
for a in data:
for b in a['results']:
#Fix why none is not working
#shitty workaround with length of 4?
if 'None' in b['time_stamp']:
timestamp.append(b['snippet'][0:12])
else:
timestamp.append(b['time_stamp'][0:12])
#Slice to appropriate date from original data
#for stamp in timestamp:
#Pattern => 11 or 12 characters. the next character is a space.
#Better way is to find 2016 or 2017 and then slice till that point
for what in timestamp:
pprint(what)
#Process data using regex to get subreddits
subReddits=[]
for y in links:
subReddits.append(y.split('/')[4])
# Path = where the "chromedriver" file is
browser = webdriver.Chrome(executable_path='/usr/bin/chromedriver')
browser.get('https://www.reddit.com/reddits')
#Get info on each search term
inputBox = browser.find_element_by_name("q")
info = []
for channel in subReddits:
inputBox.clear()
inputBox.send_keys(channel)
inputBox.send_keys(Keys.ENTER)
time.sleep(3)
#find element
info.append(browser.find_elements_by_class_name("md")[1].text)
#Combine Data for data processing
arrays = zip(links, subReddits, timestamp, info)
df = pd.DataFrame(data=arrays)
And that’s it! ^_^
Later, I plan to categorize each of these links using a bags of words algorithm.
Thanks for reading!
16 Dec 2017
In my research on the platform Discord, I had gathered a list of URLs mentioned the platform during the beginning of Discord’s rise in popularity. I wanted to investigate how Discord grew on Reddit.
After gathering a list of those URLs using a Google Scraper I had modified, I then needed to extract the URLs from that data to then get a list of subreddits where the Discord platform was being mentioned on.
The data I collected looked like this:
[{
"effective_query": "",
"id": "1721",
"no_results": "False",
"num_results": "10",
"num_results_for_query": "About 2,150,000 results (0.33 seconds)\u00a0",
"page_number": "9",
"query": "discord.gg site:reddit.com",
"requested_at": "2017-11-21 06:58:48.987283",
"requested_by": "localhost",
"results": [
{
"domain": "www.reddit.com",
"id": "2665",
"link": "https://www.reddit.com/r/HeistTeams/comments/6543q7/join_heistteams_offical_discord_server_invite/",
"link_type": "results",
"rank": "1",
"serp_id": "1721",
"snippet": "http://discord.gg/gtao. ... The good thing about discord is if you're like me and your Mic don't work there's a .... Sub still kinda active, but the discord is much more.",
"time_stamp": "Apr 13, 2017 - 100+ posts - \u200e100+ authors",
"title": "Join HeistTeam's Offical Discord Server! Invite: discord.gg/gtao - Reddit",
"visible_link": "https://www.reddit.com/r/HeistTeams/.../join_heistteams_offical_discord_server_invite..."
},
{
"domain": "www.reddit.com",
"id": "2666",
"link": "https://www.reddit.com/r/NeebsGaming/comments/6q3wlk/the_official_neebs_gaming_discord/",
"link_type": "results",
"rank": "2",
"serp_id": "1721",
"snippet": "Ive changed the link in the sidebar over to the official discord or you can join it by following this link here. http://discord.gg/neebsgaming. Here are the rules for\u00a0...",
"time_stamp": "Jul 28, 2017 - 5 posts - \u200e4 authors",
"title": "The Official Neebs Gaming Discord! : NeebsGaming - Reddit",
"visible_link": "https://www.reddit.com/r/NeebsGaming/.../the_official_neebs_gaming_discord/"
},
I first needed to extract solely the links from the “results” part of the data. So, I used a simple nested for loop to extract just the links. Then, I appended those links’ values to an empty list which will be used later on:
#Load Json
data = json.load(open('discordgg/November2015December2016.json'))
#Get Only Links from JSON
links=[]
for a in data:
for b in a['results']:
links.append(b['link'])
#pprint(b['link'])
Then, I needed to somehow just extract the part of the url that corresponds to the subreddit name. For example, for the url “https://www.reddit.com/r/NeebsGaming/comments/6q3wlk/the_official_neebs_gaming_discord/”, I wanted to extract just “NeebsGaming”. Luckily, all of the links I collected from Reddit followed the same pattern where the subreddit name appeared between “/r/” and the next “/”, so I just used regex to splice and then just selected the correct index of that slice for the list of links:
#Process data using regex to get subreddits
subReddits=[]
for y in links:
subReddits.append(y.split('/')[4])
pprint(y.split('/')[4])
Code in its totality:
import urllib, json
from pprint import pprint
#Load Json
data = json.load(open('discordgg/November2015December2016.json'))
#Get Only Links from JSON
links=[]
for a in data:
for b in a['results']:
links.append(b['link'])
#pprint(b['link'])
#Process data using regex to get subreddits
subReddits=[]
for y in links:
subReddits.append(y.split('/')[4])
pprint(y.split('/')[4])
Right now, I’m using the Reddit API and getting short descriptions of those subreddits and then using a simple bags of words algorithm to categorize them. Stay tooned!